









왜 ‘데이터 저널리즘’인가?
입력 2015.03.01 (17:10)
수정 2015.03.01 (17:36)
읽어주기 기능은 크롬기반의
브라우저에서만 사용하실 수 있습니다.
![[그 때 그 뉴스] 백범 암살범 안두희 피살](https://news.kbs.co.kr/data/news/2015/03/01/3028271_20.jpg)
<앵커 멘트>
데이터 저널리즘이라는 말 들어보셨습니까?
요즘 국내외를 막론하고 언론사들마다 기사를 작성하는 데 각종 데이터를 기반으로 활용하는 일이 잦아지면서 생겨난 용어입니다.
오늘은 먼저 데이터 저널리즘이란 무엇이고, 이것이 언론과 뉴스 이용자들에게 어떤 변화를 가져오고 있는지 살펴보겠습니다.
류란 기자가 나와 있습니다.
<질문>
류란 기자! 먼저 데이터 저널리즘, 이 용어가 생소한 분들이 많을 텐데 개념부터 알아볼까요?
<답변>
요즘 '빅데이터' 얘기 많이 들으시죠? 빅데이터란 디지털 환경에서 만들어지는 방대한 규모의 데이터를 말하는데, 단순히 양만 많은 게 아니라 종류도 다양해져서 SNS나 위치정보 같은 것도 포함됩니다.
'데이터 저널리즘'을 아주 간단하게 이해하자면, 바로 이런 빅데이터를 기자가 모으고, 다양하게 활용해서, 보도하는 것까지 합한 개념인데요, 대표적인 기사를 보면 더 쉽게 이해가 되실 겁니다.
<리포트>
지난달 9일, 원세훈 전 국정원장의 대선 개입 혐의에 대해 2심 재판부가 유죄를 선고했습니다.
국정원 직원들이 트위터에 올린 글 27만 개를 증거로 인정했습니다.
그런데 이런 트위터 글을 올린 사람 중 한 명이 국정원 직원이란 사실은, 2년 전 한 인터넷 언론이 처음으로 밝혀냈습니다.
<녹취> 뉴스타파 (2013.05.17) : "핵심 계정의 실제 사용자가 심리정보국 소속이었던 국정원 직원으로 확인됨에 따라 다른 핵심 계정은 물론 660여 개로 구성된 전체 네트워크도 국정원의 작품일 가능성이 높습니다.“
관련성이 의심되는 트위터 글과 작성자의 데이터 28만 건을 자체 분석해 확인한 겁니다.
검찰도 당시 보도가 수사에 도움이 된 것을 인정했습니다.
<녹취> 뉴스타파 (02.10) : “SNS 하실 때 의심계정은 어떻게 파악하신 거예요? 혹시 저희 뉴스타파 보도도 도움이 됐나 싶어서요. (검찰 관계자) 네. 도움이 됐습니다.“
또 다른 사례입니다.
<녹취> KBS 뉴스9 (01.24) : “KBS가 교통사고 데이터 수십만 건을 분석해 봤더니요, 유독 밤에 사고가 많이 나는 곳이 따로 있었습니다.”
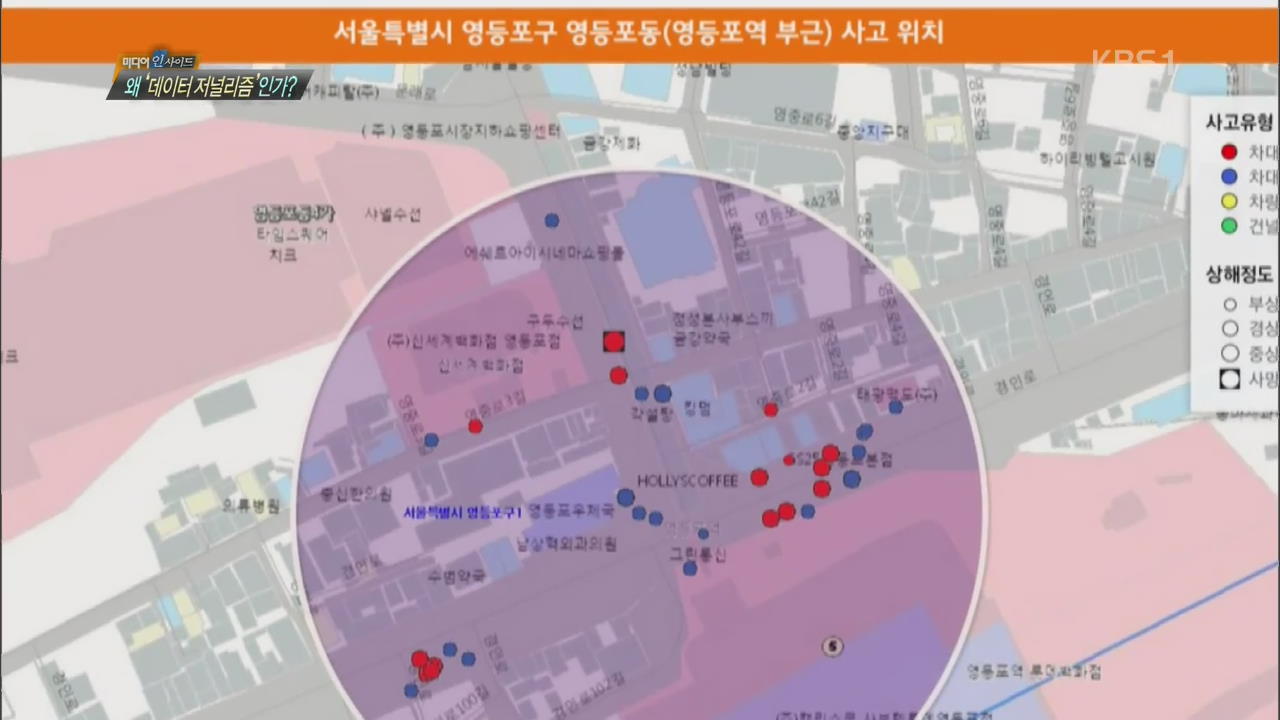
KBS 데이터 저널리즘팀이 도로교통공단에 축적된 데이터들 가운데 야간에 반경 150미터를 기준으로 1년간 교통사고가 30건 이상 발생한 지역만 골라냈더니 전국적으로 57곳이 이 같은 위험지역으로 확인됐습니다.
이 내용을 지도로 제작해 지점을 클릭하면 정확한 사고 위치가 표시되고 발생 건수와 사망자 수, 피해의 정도까지 알 수 있도록 했습니다.
전국에서 야간 교통사고가 가장 많이 나는 곳이 서울 강남의 한 사거리라는 점도 처음으로 알아냈습니다.
이처럼 엄청나게 쏟아지는 데이터 더미에서 연관성 있는 데이터들만 찾아내 이제까지 없던 새로운 정보를 찾아내는 것이 바로 '데이터 저널리즘'입니다.
<질문>
방대한 데이터를 분석해 취재한다는 건데, 그렇지만 통계 수치 등을 기사에 활용하는 건 오래 전부터 쓰던 방식 아닌가요?
<답변>
맞습니다. 데이터를 기반으로 한다는 점에서 보면 예전의 컴퓨터를 활용한 취재.보도와 별반 다를 게 없습니다.
하지만‘데이터 저널리즘’은 크게 두 가지 측면에서 단순히 데이터를 활용하는 것과는 차이가 있습니다.
<리포트>
데이터 저널리즘이 이제까지의‘데이터 활용 보도’와 다르다고 보는 관점 중 하나는, 데이터가 보조 수단이 아닌 그 자체로 주제이자 핵심이라는 겁니다.
<인터뷰> 신동희 (성균관대 대학원/인터랙션사이언스학과 교수) : "그러니까 방법론으로서의 데이터 저널리즘이 아니라는 거죠. 기사에 어떤 그래픽을 넣고 인포그래픽을 넣고 통계수치를 넣는 것 자체가 데이터 저널리즘이 아니라, 오히려 그 주종의 관계가 바뀌어야 된다는 거죠. 데이터를 통해서 스토리가 나와야 된다는 거죠."
디지털 저널리즘을 달리 보는 두 번째 관점은, 데이터의 핵심 주체가 정부기관에서 언론사와 기자로 뒤바뀌었다는 점에 주목합니다.
즉, 정부가 제공하는 데이터 안에서 얘깃거리를 찾는 게 아니라, 산발적으로 흩어진 데이터들을 기자들이 직접 분석해 새로운 사실을 찾아낸다는 측면입니다.
<인터뷰> 김태형 (KBS 데이터저널리즘팀 기자) : “기자들이 직접 데이터를 찾아내서 보도하기 때문에 기본적으로 데이터 저널리즘팀이 만들어낸 뉴스는 다른 데 없는, 다른 데선 볼 수 없는 뉴습니다. 보도자료를 좀 더 분석하거나 해서 나온 뉴스가 아니라, 어딘가에 숨어 있는 데이터를 찾아내 보도하는 거죠.”
이러다 보니 지금까지는 받아 쓸 수밖에 없었던 정부의 발표를, 역으로 검증하는 수준까지 가능해졌습니다.
한 예로, 우리나라에서 가장 공신력 있는 부동산 시세 정보는 국토부가 공개하는 실거래갑니다.
그런데 이게 엉터리였다는 걸 한 언론사가 9년치 가격 정보를 수집하고 비교분석해 밝혀내기도 했습니다.
<녹취> 뉴스타파 (01.09 국토교통부 실거래가 담당자) : “오류를 지금 수정 중에 있고요, 수정할 수 있게 도와주셔서 감사합니다.”
<인터뷰> 김태형 (KBS 데이터저널리즘팀 기자) : "보도자료 자체가 또 데이터가 바탕이 된 보도자료가 되게 많아요. 근데 거기에 들어가 있는 데이터로는 특정 이해관계가 얽혀 있는 경우가 많은 거죠. 그런 건 거꾸로 언론에서 이 데이터 활용이 올바르게 적용이 된 건지 검증을 해주는 작업이 필요합니다"
<질문>
데이터를 기반으로 검증된 사실을 보도하면 그만큼 객관성과 정확성을 높일 수 있지 않습니까. 그렇다면 해외에선 데이터 저널리즘이 어떻게 활용되고 있습니까?
<답변>
우리나라는 저널리즘의 기본인 권력과 정부에 대한 감시와 비판에 좀 더 집중하는 데 비해,
영국이나 미국에선 의료 체계나 빈곤 문제 같은 사회 기반 시스템에 주목하는 경향이 뚜렷합니다. 또 뉴스 소비자들을 직접 참여시키기 위한 노력이 다양하게 시도되고 있습니다.
<리포트>
2008년에 설립된 미국의 비영리 탐사보도 매체, '프로퍼블리카'
퓰리처상을 받은 최초의 인터넷 언론이자, 기자 한 명이 1년간 쓰는 평균 기사 수가 3개에 불과할 정도로 지독한 취재와 정보수집을 바탕으로 탐사보도의 표본으로 급부상하고 있습니다.
<녹취> "오로지 독자의 신뢰만을 추구"
미국 전역의 의료인 160만 명이 작성한 처방전 12억 건을 분석한 보도가 그 대표적인 사롑니다.
의사들이 대형 제약회사로부터 큰 후원금을 받고 그 대가성으로 해당 브랜드의 값비싼 약을 처방해주고 있다고 연속 보도했는데, 여기에 그치지 않고 자료를 데이터베이스로 구축해 개방했습니다.
독자들이 자신의 주치의나, 관심 지역을 검색하면 문제 있는 의사와 처방된 약품명, 가격까지 확인할 수 있습니다.
미주 한인사회도 여기서 한인 의사들을 검색한 뒤 그 결과를 공유했습니다.
<녹취> LA중앙일보 (2014년 4월 11일) : "이 데이터베이스에 본지 조사 대상인 한인 의사 260명을 검색한 결과 85명이 제약회사로부터 후원금을 받았다. 셋 중 한 명꼴이다."
이처럼 데이터 저널리즘이 미국과 영국에서 융성할 수 있는 건, 활용 가능한 형태의 가치 있는 데이터가 많기 때문입니다.
미국과 영국은 이미 5-6년 전 방대한 공공 데이터를 축적하는 단일한 체제를 갖췄습니다. 그리고 정부기관의 데이터를 활용가능한 형태로, 가능한 통일된 양식으로 제공하고 있습니다.
정부뿐만 아니라 언론 스스로도 데이터가 지닌 맹점을 늘 경계할 때 언론으로서 신뢰와 가치를 유지할 수 있다고, 전문가들은 조언합니다.
<인터뷰> 신동희 (성균관대 대학원 인터랙션사이언스학과 교수) : "데이터 저널리즘이 진정한 저널리즘의 하나의 모델로서 정착되기 위해서는 전적인 투명성의 확보가 이루어져야 됩니다. 정부가 정보를 데이터를 공개하고자 하는 어떤 의지와 언론사 간에도 우리가 데이터를 이렇게 해석을 했다. 이렇게 데이터를 모아서 이런 식으로 분석을 했다는, 어떤 그 과정에 대한 절차가 확보가 돼야 되고..."
<질문>
언론이 데이터를 기반으로 좋은 기사를 쓰려면 우선 미국과 영국처럼 공공 데이터를 축적해 공개하는 게 중요하다는 얘긴데, 우리나라의 상황은 어떻습니까?
<답변>
아직은 갈 길이 멀다는 게 언론계 전반적인 분위기입니다. 질문 하나 드려볼게요. 다음 달이죠, 매년 3월이면 고위 공직자 재산공개가 이뤄지는데, 정부가 공개하는 공식 문서는 어떻게 볼 수 있을까요?
<질문>
관보나 정부 사이트에서 볼 수 있지 않나요?
<답변>
맞습니다. 그럼 보통 인터넷 포털 사이트에서, '국회의원 재산공개' 등으로 검색을 하면 그 사이트나 문서가 나와야 되지 않습니까? 그런데 아무리 검색을 해도 정부 사이트나 공식 문서는 찾을 수 없었는데요, 그 이유가 좀 황당합니다.
<리포트>
대표 인터넷 포털 두 곳에서 다양한 검색어로 입력해봤습니다.
개인 블로그와 카페만 검색되고, 공신력 있는 정부의 공식 사이트나 문서는 어디에서도 찾을 수 없습니다.
사이트 검색이 차단돼 있기 때문입니다.
<인터뷰> 신동희 (성균관대 대학원 인터랙션사이언스학과 교수) : “가장 큰 문제는, 공개된 데이터인데 대중들이 그 정보를 쉽게 접근할 수 없다는 것이죠. 정부는 이제 웹사이트를 통해서 공개를 했다고 하지만, 그런 것들이 어떤 글자가 작은 형태로 되어 있다거나 심지어 우리가 검색할 수 없는 형태의 데이터라는 것이죠.”
고위 공직자의 재산 내역은 법에 명시된 공개 정보지만 포털 사이트가 데이터 검색의 80%를 차지하는 우리나라의 특성상 이 정보는 비공개 정보인 셈입니다.
어렵게 찾아내도 문제입니다. 대부분 데이터가 활용하기 어려운 PDF 파일 형식으로 돼 있습니다.
<인터뷰> 권혜진 (뉴스타파 데이터저널리즘연구소 소장) : "PDF에 있는 자료들은 기계가 읽을 수 있는 형태가 아니죠. 따라서 검색하기가 어렵습니다. 그래서 공개는 했는데 검색이 안 되는 경우도 굉장히 많죠. 아쉬운 점은 국민들이 알고 싶어 하는, 뉴스 가치가 큰 그런 정보들은 여전히 접근하기가 어렵고 불편하게 돼 있단 사실입니다."
이뿐만이 아닙니다. 재산 관련 페이지만 삭제해 버렸거나, 몽땅 백지로 올려놓은 경우도 있습니다.
우리 정부는 지난 2013년 공공 정보를 적극 개방, 공유하겠다며 ‘정부 3.0’ 추진 계획을 발표했습니다.
국가 기관의 모든 정보는 공개를 원칙으로 하고 공개 문서는 생산과 동시에 원문까지 공개하는 등 구체적인 내용이 담겼습니다.
하지만 1년 반이 지난 지금도 여전히 미흡하다는 평갑니다.
그러다 보니 언론도 고전 중입니다.
데이터 저널리즘을 주창하며 과감히 전담 부서를 편성한 언론사 가운데 지금도 기사를 꾸준히 내놓으며 조직을 유지하는 곳은 거의 없습니다.
<인터뷰> 박대민 (한국언론재단 선임연구원) : "이렇게 데이터를 활용하기가 힘들고 여러 가지 풀어야 할 사항들도 많고 이런 상황에서, 자체 자원이나 인력을 새롭게 투자해서 분석에 들어가기 쉽지 않은 상황이 된 겁니다. 인적, 금전적으로 여기에 투입할 만한 여력이 있는 언론사가 많지 않은 거죠"
데이터 자체가 갖고 있는 가치와 의미는 갈수록 중요해지고 있습니다.
하지만 역시 중요한 것은, 기자가 현장을 발로 뛰고 정확한 시각과 판단을 갖추고 데이터의 이면을 들여다 볼 때, 비로소 진정한 데이터 저널리즘도 실현될 수 있습니다.
데이터 저널리즘이라는 말 들어보셨습니까?
요즘 국내외를 막론하고 언론사들마다 기사를 작성하는 데 각종 데이터를 기반으로 활용하는 일이 잦아지면서 생겨난 용어입니다.
오늘은 먼저 데이터 저널리즘이란 무엇이고, 이것이 언론과 뉴스 이용자들에게 어떤 변화를 가져오고 있는지 살펴보겠습니다.
류란 기자가 나와 있습니다.
<질문>
류란 기자! 먼저 데이터 저널리즘, 이 용어가 생소한 분들이 많을 텐데 개념부터 알아볼까요?
<답변>
요즘 '빅데이터' 얘기 많이 들으시죠? 빅데이터란 디지털 환경에서 만들어지는 방대한 규모의 데이터를 말하는데, 단순히 양만 많은 게 아니라 종류도 다양해져서 SNS나 위치정보 같은 것도 포함됩니다.
'데이터 저널리즘'을 아주 간단하게 이해하자면, 바로 이런 빅데이터를 기자가 모으고, 다양하게 활용해서, 보도하는 것까지 합한 개념인데요, 대표적인 기사를 보면 더 쉽게 이해가 되실 겁니다.
<리포트>
지난달 9일, 원세훈 전 국정원장의 대선 개입 혐의에 대해 2심 재판부가 유죄를 선고했습니다.
국정원 직원들이 트위터에 올린 글 27만 개를 증거로 인정했습니다.
그런데 이런 트위터 글을 올린 사람 중 한 명이 국정원 직원이란 사실은, 2년 전 한 인터넷 언론이 처음으로 밝혀냈습니다.
<녹취> 뉴스타파 (2013.05.17) : "핵심 계정의 실제 사용자가 심리정보국 소속이었던 국정원 직원으로 확인됨에 따라 다른 핵심 계정은 물론 660여 개로 구성된 전체 네트워크도 국정원의 작품일 가능성이 높습니다.“
관련성이 의심되는 트위터 글과 작성자의 데이터 28만 건을 자체 분석해 확인한 겁니다.
검찰도 당시 보도가 수사에 도움이 된 것을 인정했습니다.
<녹취> 뉴스타파 (02.10) : “SNS 하실 때 의심계정은 어떻게 파악하신 거예요? 혹시 저희 뉴스타파 보도도 도움이 됐나 싶어서요. (검찰 관계자) 네. 도움이 됐습니다.“
또 다른 사례입니다.
<녹취> KBS 뉴스9 (01.24) : “KBS가 교통사고 데이터 수십만 건을 분석해 봤더니요, 유독 밤에 사고가 많이 나는 곳이 따로 있었습니다.”
KBS 데이터 저널리즘팀이 도로교통공단에 축적된 데이터들 가운데 야간에 반경 150미터를 기준으로 1년간 교통사고가 30건 이상 발생한 지역만 골라냈더니 전국적으로 57곳이 이 같은 위험지역으로 확인됐습니다.
이 내용을 지도로 제작해 지점을 클릭하면 정확한 사고 위치가 표시되고 발생 건수와 사망자 수, 피해의 정도까지 알 수 있도록 했습니다.
전국에서 야간 교통사고가 가장 많이 나는 곳이 서울 강남의 한 사거리라는 점도 처음으로 알아냈습니다.
이처럼 엄청나게 쏟아지는 데이터 더미에서 연관성 있는 데이터들만 찾아내 이제까지 없던 새로운 정보를 찾아내는 것이 바로 '데이터 저널리즘'입니다.
<질문>
방대한 데이터를 분석해 취재한다는 건데, 그렇지만 통계 수치 등을 기사에 활용하는 건 오래 전부터 쓰던 방식 아닌가요?
<답변>
맞습니다. 데이터를 기반으로 한다는 점에서 보면 예전의 컴퓨터를 활용한 취재.보도와 별반 다를 게 없습니다.
하지만‘데이터 저널리즘’은 크게 두 가지 측면에서 단순히 데이터를 활용하는 것과는 차이가 있습니다.
<리포트>
데이터 저널리즘이 이제까지의‘데이터 활용 보도’와 다르다고 보는 관점 중 하나는, 데이터가 보조 수단이 아닌 그 자체로 주제이자 핵심이라는 겁니다.
<인터뷰> 신동희 (성균관대 대학원/인터랙션사이언스학과 교수) : "그러니까 방법론으로서의 데이터 저널리즘이 아니라는 거죠. 기사에 어떤 그래픽을 넣고 인포그래픽을 넣고 통계수치를 넣는 것 자체가 데이터 저널리즘이 아니라, 오히려 그 주종의 관계가 바뀌어야 된다는 거죠. 데이터를 통해서 스토리가 나와야 된다는 거죠."
디지털 저널리즘을 달리 보는 두 번째 관점은, 데이터의 핵심 주체가 정부기관에서 언론사와 기자로 뒤바뀌었다는 점에 주목합니다.
즉, 정부가 제공하는 데이터 안에서 얘깃거리를 찾는 게 아니라, 산발적으로 흩어진 데이터들을 기자들이 직접 분석해 새로운 사실을 찾아낸다는 측면입니다.
<인터뷰> 김태형 (KBS 데이터저널리즘팀 기자) : “기자들이 직접 데이터를 찾아내서 보도하기 때문에 기본적으로 데이터 저널리즘팀이 만들어낸 뉴스는 다른 데 없는, 다른 데선 볼 수 없는 뉴습니다. 보도자료를 좀 더 분석하거나 해서 나온 뉴스가 아니라, 어딘가에 숨어 있는 데이터를 찾아내 보도하는 거죠.”
이러다 보니 지금까지는 받아 쓸 수밖에 없었던 정부의 발표를, 역으로 검증하는 수준까지 가능해졌습니다.
한 예로, 우리나라에서 가장 공신력 있는 부동산 시세 정보는 국토부가 공개하는 실거래갑니다.
그런데 이게 엉터리였다는 걸 한 언론사가 9년치 가격 정보를 수집하고 비교분석해 밝혀내기도 했습니다.
<녹취> 뉴스타파 (01.09 국토교통부 실거래가 담당자) : “오류를 지금 수정 중에 있고요, 수정할 수 있게 도와주셔서 감사합니다.”
<인터뷰> 김태형 (KBS 데이터저널리즘팀 기자) : "보도자료 자체가 또 데이터가 바탕이 된 보도자료가 되게 많아요. 근데 거기에 들어가 있는 데이터로는 특정 이해관계가 얽혀 있는 경우가 많은 거죠. 그런 건 거꾸로 언론에서 이 데이터 활용이 올바르게 적용이 된 건지 검증을 해주는 작업이 필요합니다"
<질문>
데이터를 기반으로 검증된 사실을 보도하면 그만큼 객관성과 정확성을 높일 수 있지 않습니까. 그렇다면 해외에선 데이터 저널리즘이 어떻게 활용되고 있습니까?
<답변>
우리나라는 저널리즘의 기본인 권력과 정부에 대한 감시와 비판에 좀 더 집중하는 데 비해,
영국이나 미국에선 의료 체계나 빈곤 문제 같은 사회 기반 시스템에 주목하는 경향이 뚜렷합니다. 또 뉴스 소비자들을 직접 참여시키기 위한 노력이 다양하게 시도되고 있습니다.
<리포트>
2008년에 설립된 미국의 비영리 탐사보도 매체, '프로퍼블리카'
퓰리처상을 받은 최초의 인터넷 언론이자, 기자 한 명이 1년간 쓰는 평균 기사 수가 3개에 불과할 정도로 지독한 취재와 정보수집을 바탕으로 탐사보도의 표본으로 급부상하고 있습니다.
<녹취> "오로지 독자의 신뢰만을 추구"
미국 전역의 의료인 160만 명이 작성한 처방전 12억 건을 분석한 보도가 그 대표적인 사롑니다.
의사들이 대형 제약회사로부터 큰 후원금을 받고 그 대가성으로 해당 브랜드의 값비싼 약을 처방해주고 있다고 연속 보도했는데, 여기에 그치지 않고 자료를 데이터베이스로 구축해 개방했습니다.
독자들이 자신의 주치의나, 관심 지역을 검색하면 문제 있는 의사와 처방된 약품명, 가격까지 확인할 수 있습니다.
미주 한인사회도 여기서 한인 의사들을 검색한 뒤 그 결과를 공유했습니다.
<녹취> LA중앙일보 (2014년 4월 11일) : "이 데이터베이스에 본지 조사 대상인 한인 의사 260명을 검색한 결과 85명이 제약회사로부터 후원금을 받았다. 셋 중 한 명꼴이다."
이처럼 데이터 저널리즘이 미국과 영국에서 융성할 수 있는 건, 활용 가능한 형태의 가치 있는 데이터가 많기 때문입니다.
미국과 영국은 이미 5-6년 전 방대한 공공 데이터를 축적하는 단일한 체제를 갖췄습니다. 그리고 정부기관의 데이터를 활용가능한 형태로, 가능한 통일된 양식으로 제공하고 있습니다.
정부뿐만 아니라 언론 스스로도 데이터가 지닌 맹점을 늘 경계할 때 언론으로서 신뢰와 가치를 유지할 수 있다고, 전문가들은 조언합니다.
<인터뷰> 신동희 (성균관대 대학원 인터랙션사이언스학과 교수) : "데이터 저널리즘이 진정한 저널리즘의 하나의 모델로서 정착되기 위해서는 전적인 투명성의 확보가 이루어져야 됩니다. 정부가 정보를 데이터를 공개하고자 하는 어떤 의지와 언론사 간에도 우리가 데이터를 이렇게 해석을 했다. 이렇게 데이터를 모아서 이런 식으로 분석을 했다는, 어떤 그 과정에 대한 절차가 확보가 돼야 되고..."
<질문>
언론이 데이터를 기반으로 좋은 기사를 쓰려면 우선 미국과 영국처럼 공공 데이터를 축적해 공개하는 게 중요하다는 얘긴데, 우리나라의 상황은 어떻습니까?
<답변>
아직은 갈 길이 멀다는 게 언론계 전반적인 분위기입니다. 질문 하나 드려볼게요. 다음 달이죠, 매년 3월이면 고위 공직자 재산공개가 이뤄지는데, 정부가 공개하는 공식 문서는 어떻게 볼 수 있을까요?
<질문>
관보나 정부 사이트에서 볼 수 있지 않나요?
<답변>
맞습니다. 그럼 보통 인터넷 포털 사이트에서, '국회의원 재산공개' 등으로 검색을 하면 그 사이트나 문서가 나와야 되지 않습니까? 그런데 아무리 검색을 해도 정부 사이트나 공식 문서는 찾을 수 없었는데요, 그 이유가 좀 황당합니다.
<리포트>
대표 인터넷 포털 두 곳에서 다양한 검색어로 입력해봤습니다.
개인 블로그와 카페만 검색되고, 공신력 있는 정부의 공식 사이트나 문서는 어디에서도 찾을 수 없습니다.
사이트 검색이 차단돼 있기 때문입니다.
<인터뷰> 신동희 (성균관대 대학원 인터랙션사이언스학과 교수) : “가장 큰 문제는, 공개된 데이터인데 대중들이 그 정보를 쉽게 접근할 수 없다는 것이죠. 정부는 이제 웹사이트를 통해서 공개를 했다고 하지만, 그런 것들이 어떤 글자가 작은 형태로 되어 있다거나 심지어 우리가 검색할 수 없는 형태의 데이터라는 것이죠.”
고위 공직자의 재산 내역은 법에 명시된 공개 정보지만 포털 사이트가 데이터 검색의 80%를 차지하는 우리나라의 특성상 이 정보는 비공개 정보인 셈입니다.
어렵게 찾아내도 문제입니다. 대부분 데이터가 활용하기 어려운 PDF 파일 형식으로 돼 있습니다.
<인터뷰> 권혜진 (뉴스타파 데이터저널리즘연구소 소장) : "PDF에 있는 자료들은 기계가 읽을 수 있는 형태가 아니죠. 따라서 검색하기가 어렵습니다. 그래서 공개는 했는데 검색이 안 되는 경우도 굉장히 많죠. 아쉬운 점은 국민들이 알고 싶어 하는, 뉴스 가치가 큰 그런 정보들은 여전히 접근하기가 어렵고 불편하게 돼 있단 사실입니다."
이뿐만이 아닙니다. 재산 관련 페이지만 삭제해 버렸거나, 몽땅 백지로 올려놓은 경우도 있습니다.
우리 정부는 지난 2013년 공공 정보를 적극 개방, 공유하겠다며 ‘정부 3.0’ 추진 계획을 발표했습니다.
국가 기관의 모든 정보는 공개를 원칙으로 하고 공개 문서는 생산과 동시에 원문까지 공개하는 등 구체적인 내용이 담겼습니다.
하지만 1년 반이 지난 지금도 여전히 미흡하다는 평갑니다.
그러다 보니 언론도 고전 중입니다.
데이터 저널리즘을 주창하며 과감히 전담 부서를 편성한 언론사 가운데 지금도 기사를 꾸준히 내놓으며 조직을 유지하는 곳은 거의 없습니다.
<인터뷰> 박대민 (한국언론재단 선임연구원) : "이렇게 데이터를 활용하기가 힘들고 여러 가지 풀어야 할 사항들도 많고 이런 상황에서, 자체 자원이나 인력을 새롭게 투자해서 분석에 들어가기 쉽지 않은 상황이 된 겁니다. 인적, 금전적으로 여기에 투입할 만한 여력이 있는 언론사가 많지 않은 거죠"
데이터 자체가 갖고 있는 가치와 의미는 갈수록 중요해지고 있습니다.
하지만 역시 중요한 것은, 기자가 현장을 발로 뛰고 정확한 시각과 판단을 갖추고 데이터의 이면을 들여다 볼 때, 비로소 진정한 데이터 저널리즘도 실현될 수 있습니다.
■ 제보하기
▷ 카카오톡 : 'KBS제보' 검색, 채널 추가
▷ 전화 : 02-781-1234, 4444
▷ 이메일 : kbs1234@kbs.co.kr
▷ 유튜브, 네이버, 카카오에서도 KBS뉴스를 구독해주세요!
- 왜 ‘데이터 저널리즘’인가?
-
- 입력 2015-03-01 15:40:52
- 수정2015-03-01 17:36:44
<앵커 멘트>
데이터 저널리즘이라는 말 들어보셨습니까?
요즘 국내외를 막론하고 언론사들마다 기사를 작성하는 데 각종 데이터를 기반으로 활용하는 일이 잦아지면서 생겨난 용어입니다.
오늘은 먼저 데이터 저널리즘이란 무엇이고, 이것이 언론과 뉴스 이용자들에게 어떤 변화를 가져오고 있는지 살펴보겠습니다.
류란 기자가 나와 있습니다.
<질문>
류란 기자! 먼저 데이터 저널리즘, 이 용어가 생소한 분들이 많을 텐데 개념부터 알아볼까요?
<답변>
요즘 '빅데이터' 얘기 많이 들으시죠? 빅데이터란 디지털 환경에서 만들어지는 방대한 규모의 데이터를 말하는데, 단순히 양만 많은 게 아니라 종류도 다양해져서 SNS나 위치정보 같은 것도 포함됩니다.
'데이터 저널리즘'을 아주 간단하게 이해하자면, 바로 이런 빅데이터를 기자가 모으고, 다양하게 활용해서, 보도하는 것까지 합한 개념인데요, 대표적인 기사를 보면 더 쉽게 이해가 되실 겁니다.
<리포트>
지난달 9일, 원세훈 전 국정원장의 대선 개입 혐의에 대해 2심 재판부가 유죄를 선고했습니다.
국정원 직원들이 트위터에 올린 글 27만 개를 증거로 인정했습니다.
그런데 이런 트위터 글을 올린 사람 중 한 명이 국정원 직원이란 사실은, 2년 전 한 인터넷 언론이 처음으로 밝혀냈습니다.
<녹취> 뉴스타파 (2013.05.17) : "핵심 계정의 실제 사용자가 심리정보국 소속이었던 국정원 직원으로 확인됨에 따라 다른 핵심 계정은 물론 660여 개로 구성된 전체 네트워크도 국정원의 작품일 가능성이 높습니다.“
관련성이 의심되는 트위터 글과 작성자의 데이터 28만 건을 자체 분석해 확인한 겁니다.
검찰도 당시 보도가 수사에 도움이 된 것을 인정했습니다.
<녹취> 뉴스타파 (02.10) : “SNS 하실 때 의심계정은 어떻게 파악하신 거예요? 혹시 저희 뉴스타파 보도도 도움이 됐나 싶어서요. (검찰 관계자) 네. 도움이 됐습니다.“
또 다른 사례입니다.
<녹취> KBS 뉴스9 (01.24) : “KBS가 교통사고 데이터 수십만 건을 분석해 봤더니요, 유독 밤에 사고가 많이 나는 곳이 따로 있었습니다.”
KBS 데이터 저널리즘팀이 도로교통공단에 축적된 데이터들 가운데 야간에 반경 150미터를 기준으로 1년간 교통사고가 30건 이상 발생한 지역만 골라냈더니 전국적으로 57곳이 이 같은 위험지역으로 확인됐습니다.
이 내용을 지도로 제작해 지점을 클릭하면 정확한 사고 위치가 표시되고 발생 건수와 사망자 수, 피해의 정도까지 알 수 있도록 했습니다.
전국에서 야간 교통사고가 가장 많이 나는 곳이 서울 강남의 한 사거리라는 점도 처음으로 알아냈습니다.
이처럼 엄청나게 쏟아지는 데이터 더미에서 연관성 있는 데이터들만 찾아내 이제까지 없던 새로운 정보를 찾아내는 것이 바로 '데이터 저널리즘'입니다.
<질문>
방대한 데이터를 분석해 취재한다는 건데, 그렇지만 통계 수치 등을 기사에 활용하는 건 오래 전부터 쓰던 방식 아닌가요?
<답변>
맞습니다. 데이터를 기반으로 한다는 점에서 보면 예전의 컴퓨터를 활용한 취재.보도와 별반 다를 게 없습니다.
하지만‘데이터 저널리즘’은 크게 두 가지 측면에서 단순히 데이터를 활용하는 것과는 차이가 있습니다.
<리포트>
데이터 저널리즘이 이제까지의‘데이터 활용 보도’와 다르다고 보는 관점 중 하나는, 데이터가 보조 수단이 아닌 그 자체로 주제이자 핵심이라는 겁니다.
<인터뷰> 신동희 (성균관대 대학원/인터랙션사이언스학과 교수) : "그러니까 방법론으로서의 데이터 저널리즘이 아니라는 거죠. 기사에 어떤 그래픽을 넣고 인포그래픽을 넣고 통계수치를 넣는 것 자체가 데이터 저널리즘이 아니라, 오히려 그 주종의 관계가 바뀌어야 된다는 거죠. 데이터를 통해서 스토리가 나와야 된다는 거죠."
디지털 저널리즘을 달리 보는 두 번째 관점은, 데이터의 핵심 주체가 정부기관에서 언론사와 기자로 뒤바뀌었다는 점에 주목합니다.
즉, 정부가 제공하는 데이터 안에서 얘깃거리를 찾는 게 아니라, 산발적으로 흩어진 데이터들을 기자들이 직접 분석해 새로운 사실을 찾아낸다는 측면입니다.
<인터뷰> 김태형 (KBS 데이터저널리즘팀 기자) : “기자들이 직접 데이터를 찾아내서 보도하기 때문에 기본적으로 데이터 저널리즘팀이 만들어낸 뉴스는 다른 데 없는, 다른 데선 볼 수 없는 뉴습니다. 보도자료를 좀 더 분석하거나 해서 나온 뉴스가 아니라, 어딘가에 숨어 있는 데이터를 찾아내 보도하는 거죠.”
이러다 보니 지금까지는 받아 쓸 수밖에 없었던 정부의 발표를, 역으로 검증하는 수준까지 가능해졌습니다.
한 예로, 우리나라에서 가장 공신력 있는 부동산 시세 정보는 국토부가 공개하는 실거래갑니다.
그런데 이게 엉터리였다는 걸 한 언론사가 9년치 가격 정보를 수집하고 비교분석해 밝혀내기도 했습니다.
<녹취> 뉴스타파 (01.09 국토교통부 실거래가 담당자) : “오류를 지금 수정 중에 있고요, 수정할 수 있게 도와주셔서 감사합니다.”
<인터뷰> 김태형 (KBS 데이터저널리즘팀 기자) : "보도자료 자체가 또 데이터가 바탕이 된 보도자료가 되게 많아요. 근데 거기에 들어가 있는 데이터로는 특정 이해관계가 얽혀 있는 경우가 많은 거죠. 그런 건 거꾸로 언론에서 이 데이터 활용이 올바르게 적용이 된 건지 검증을 해주는 작업이 필요합니다"
<질문>
데이터를 기반으로 검증된 사실을 보도하면 그만큼 객관성과 정확성을 높일 수 있지 않습니까. 그렇다면 해외에선 데이터 저널리즘이 어떻게 활용되고 있습니까?
<답변>
우리나라는 저널리즘의 기본인 권력과 정부에 대한 감시와 비판에 좀 더 집중하는 데 비해,
영국이나 미국에선 의료 체계나 빈곤 문제 같은 사회 기반 시스템에 주목하는 경향이 뚜렷합니다. 또 뉴스 소비자들을 직접 참여시키기 위한 노력이 다양하게 시도되고 있습니다.
<리포트>
2008년에 설립된 미국의 비영리 탐사보도 매체, '프로퍼블리카'
퓰리처상을 받은 최초의 인터넷 언론이자, 기자 한 명이 1년간 쓰는 평균 기사 수가 3개에 불과할 정도로 지독한 취재와 정보수집을 바탕으로 탐사보도의 표본으로 급부상하고 있습니다.
<녹취> "오로지 독자의 신뢰만을 추구"
미국 전역의 의료인 160만 명이 작성한 처방전 12억 건을 분석한 보도가 그 대표적인 사롑니다.
의사들이 대형 제약회사로부터 큰 후원금을 받고 그 대가성으로 해당 브랜드의 값비싼 약을 처방해주고 있다고 연속 보도했는데, 여기에 그치지 않고 자료를 데이터베이스로 구축해 개방했습니다.
독자들이 자신의 주치의나, 관심 지역을 검색하면 문제 있는 의사와 처방된 약품명, 가격까지 확인할 수 있습니다.
미주 한인사회도 여기서 한인 의사들을 검색한 뒤 그 결과를 공유했습니다.
<녹취> LA중앙일보 (2014년 4월 11일) : "이 데이터베이스에 본지 조사 대상인 한인 의사 260명을 검색한 결과 85명이 제약회사로부터 후원금을 받았다. 셋 중 한 명꼴이다."
이처럼 데이터 저널리즘이 미국과 영국에서 융성할 수 있는 건, 활용 가능한 형태의 가치 있는 데이터가 많기 때문입니다.
미국과 영국은 이미 5-6년 전 방대한 공공 데이터를 축적하는 단일한 체제를 갖췄습니다. 그리고 정부기관의 데이터를 활용가능한 형태로, 가능한 통일된 양식으로 제공하고 있습니다.
정부뿐만 아니라 언론 스스로도 데이터가 지닌 맹점을 늘 경계할 때 언론으로서 신뢰와 가치를 유지할 수 있다고, 전문가들은 조언합니다.
<인터뷰> 신동희 (성균관대 대학원 인터랙션사이언스학과 교수) : "데이터 저널리즘이 진정한 저널리즘의 하나의 모델로서 정착되기 위해서는 전적인 투명성의 확보가 이루어져야 됩니다. 정부가 정보를 데이터를 공개하고자 하는 어떤 의지와 언론사 간에도 우리가 데이터를 이렇게 해석을 했다. 이렇게 데이터를 모아서 이런 식으로 분석을 했다는, 어떤 그 과정에 대한 절차가 확보가 돼야 되고..."
<질문>
언론이 데이터를 기반으로 좋은 기사를 쓰려면 우선 미국과 영국처럼 공공 데이터를 축적해 공개하는 게 중요하다는 얘긴데, 우리나라의 상황은 어떻습니까?
<답변>
아직은 갈 길이 멀다는 게 언론계 전반적인 분위기입니다. 질문 하나 드려볼게요. 다음 달이죠, 매년 3월이면 고위 공직자 재산공개가 이뤄지는데, 정부가 공개하는 공식 문서는 어떻게 볼 수 있을까요?
<질문>
관보나 정부 사이트에서 볼 수 있지 않나요?
<답변>
맞습니다. 그럼 보통 인터넷 포털 사이트에서, '국회의원 재산공개' 등으로 검색을 하면 그 사이트나 문서가 나와야 되지 않습니까? 그런데 아무리 검색을 해도 정부 사이트나 공식 문서는 찾을 수 없었는데요, 그 이유가 좀 황당합니다.
<리포트>
대표 인터넷 포털 두 곳에서 다양한 검색어로 입력해봤습니다.
개인 블로그와 카페만 검색되고, 공신력 있는 정부의 공식 사이트나 문서는 어디에서도 찾을 수 없습니다.
사이트 검색이 차단돼 있기 때문입니다.
<인터뷰> 신동희 (성균관대 대학원 인터랙션사이언스학과 교수) : “가장 큰 문제는, 공개된 데이터인데 대중들이 그 정보를 쉽게 접근할 수 없다는 것이죠. 정부는 이제 웹사이트를 통해서 공개를 했다고 하지만, 그런 것들이 어떤 글자가 작은 형태로 되어 있다거나 심지어 우리가 검색할 수 없는 형태의 데이터라는 것이죠.”
고위 공직자의 재산 내역은 법에 명시된 공개 정보지만 포털 사이트가 데이터 검색의 80%를 차지하는 우리나라의 특성상 이 정보는 비공개 정보인 셈입니다.
어렵게 찾아내도 문제입니다. 대부분 데이터가 활용하기 어려운 PDF 파일 형식으로 돼 있습니다.
<인터뷰> 권혜진 (뉴스타파 데이터저널리즘연구소 소장) : "PDF에 있는 자료들은 기계가 읽을 수 있는 형태가 아니죠. 따라서 검색하기가 어렵습니다. 그래서 공개는 했는데 검색이 안 되는 경우도 굉장히 많죠. 아쉬운 점은 국민들이 알고 싶어 하는, 뉴스 가치가 큰 그런 정보들은 여전히 접근하기가 어렵고 불편하게 돼 있단 사실입니다."
이뿐만이 아닙니다. 재산 관련 페이지만 삭제해 버렸거나, 몽땅 백지로 올려놓은 경우도 있습니다.
우리 정부는 지난 2013년 공공 정보를 적극 개방, 공유하겠다며 ‘정부 3.0’ 추진 계획을 발표했습니다.
국가 기관의 모든 정보는 공개를 원칙으로 하고 공개 문서는 생산과 동시에 원문까지 공개하는 등 구체적인 내용이 담겼습니다.
하지만 1년 반이 지난 지금도 여전히 미흡하다는 평갑니다.
그러다 보니 언론도 고전 중입니다.
데이터 저널리즘을 주창하며 과감히 전담 부서를 편성한 언론사 가운데 지금도 기사를 꾸준히 내놓으며 조직을 유지하는 곳은 거의 없습니다.
<인터뷰> 박대민 (한국언론재단 선임연구원) : "이렇게 데이터를 활용하기가 힘들고 여러 가지 풀어야 할 사항들도 많고 이런 상황에서, 자체 자원이나 인력을 새롭게 투자해서 분석에 들어가기 쉽지 않은 상황이 된 겁니다. 인적, 금전적으로 여기에 투입할 만한 여력이 있는 언론사가 많지 않은 거죠"
데이터 자체가 갖고 있는 가치와 의미는 갈수록 중요해지고 있습니다.
하지만 역시 중요한 것은, 기자가 현장을 발로 뛰고 정확한 시각과 판단을 갖추고 데이터의 이면을 들여다 볼 때, 비로소 진정한 데이터 저널리즘도 실현될 수 있습니다.
데이터 저널리즘이라는 말 들어보셨습니까?
요즘 국내외를 막론하고 언론사들마다 기사를 작성하는 데 각종 데이터를 기반으로 활용하는 일이 잦아지면서 생겨난 용어입니다.
오늘은 먼저 데이터 저널리즘이란 무엇이고, 이것이 언론과 뉴스 이용자들에게 어떤 변화를 가져오고 있는지 살펴보겠습니다.
류란 기자가 나와 있습니다.
<질문>
류란 기자! 먼저 데이터 저널리즘, 이 용어가 생소한 분들이 많을 텐데 개념부터 알아볼까요?
<답변>
요즘 '빅데이터' 얘기 많이 들으시죠? 빅데이터란 디지털 환경에서 만들어지는 방대한 규모의 데이터를 말하는데, 단순히 양만 많은 게 아니라 종류도 다양해져서 SNS나 위치정보 같은 것도 포함됩니다.
'데이터 저널리즘'을 아주 간단하게 이해하자면, 바로 이런 빅데이터를 기자가 모으고, 다양하게 활용해서, 보도하는 것까지 합한 개념인데요, 대표적인 기사를 보면 더 쉽게 이해가 되실 겁니다.
<리포트>
지난달 9일, 원세훈 전 국정원장의 대선 개입 혐의에 대해 2심 재판부가 유죄를 선고했습니다.
국정원 직원들이 트위터에 올린 글 27만 개를 증거로 인정했습니다.
그런데 이런 트위터 글을 올린 사람 중 한 명이 국정원 직원이란 사실은, 2년 전 한 인터넷 언론이 처음으로 밝혀냈습니다.
<녹취> 뉴스타파 (2013.05.17) : "핵심 계정의 실제 사용자가 심리정보국 소속이었던 국정원 직원으로 확인됨에 따라 다른 핵심 계정은 물론 660여 개로 구성된 전체 네트워크도 국정원의 작품일 가능성이 높습니다.“
관련성이 의심되는 트위터 글과 작성자의 데이터 28만 건을 자체 분석해 확인한 겁니다.
검찰도 당시 보도가 수사에 도움이 된 것을 인정했습니다.
<녹취> 뉴스타파 (02.10) : “SNS 하실 때 의심계정은 어떻게 파악하신 거예요? 혹시 저희 뉴스타파 보도도 도움이 됐나 싶어서요. (검찰 관계자) 네. 도움이 됐습니다.“
또 다른 사례입니다.
<녹취> KBS 뉴스9 (01.24) : “KBS가 교통사고 데이터 수십만 건을 분석해 봤더니요, 유독 밤에 사고가 많이 나는 곳이 따로 있었습니다.”
KBS 데이터 저널리즘팀이 도로교통공단에 축적된 데이터들 가운데 야간에 반경 150미터를 기준으로 1년간 교통사고가 30건 이상 발생한 지역만 골라냈더니 전국적으로 57곳이 이 같은 위험지역으로 확인됐습니다.
이 내용을 지도로 제작해 지점을 클릭하면 정확한 사고 위치가 표시되고 발생 건수와 사망자 수, 피해의 정도까지 알 수 있도록 했습니다.
전국에서 야간 교통사고가 가장 많이 나는 곳이 서울 강남의 한 사거리라는 점도 처음으로 알아냈습니다.
이처럼 엄청나게 쏟아지는 데이터 더미에서 연관성 있는 데이터들만 찾아내 이제까지 없던 새로운 정보를 찾아내는 것이 바로 '데이터 저널리즘'입니다.
<질문>
방대한 데이터를 분석해 취재한다는 건데, 그렇지만 통계 수치 등을 기사에 활용하는 건 오래 전부터 쓰던 방식 아닌가요?
<답변>
맞습니다. 데이터를 기반으로 한다는 점에서 보면 예전의 컴퓨터를 활용한 취재.보도와 별반 다를 게 없습니다.
하지만‘데이터 저널리즘’은 크게 두 가지 측면에서 단순히 데이터를 활용하는 것과는 차이가 있습니다.
<리포트>
데이터 저널리즘이 이제까지의‘데이터 활용 보도’와 다르다고 보는 관점 중 하나는, 데이터가 보조 수단이 아닌 그 자체로 주제이자 핵심이라는 겁니다.
<인터뷰> 신동희 (성균관대 대학원/인터랙션사이언스학과 교수) : "그러니까 방법론으로서의 데이터 저널리즘이 아니라는 거죠. 기사에 어떤 그래픽을 넣고 인포그래픽을 넣고 통계수치를 넣는 것 자체가 데이터 저널리즘이 아니라, 오히려 그 주종의 관계가 바뀌어야 된다는 거죠. 데이터를 통해서 스토리가 나와야 된다는 거죠."
디지털 저널리즘을 달리 보는 두 번째 관점은, 데이터의 핵심 주체가 정부기관에서 언론사와 기자로 뒤바뀌었다는 점에 주목합니다.
즉, 정부가 제공하는 데이터 안에서 얘깃거리를 찾는 게 아니라, 산발적으로 흩어진 데이터들을 기자들이 직접 분석해 새로운 사실을 찾아낸다는 측면입니다.
<인터뷰> 김태형 (KBS 데이터저널리즘팀 기자) : “기자들이 직접 데이터를 찾아내서 보도하기 때문에 기본적으로 데이터 저널리즘팀이 만들어낸 뉴스는 다른 데 없는, 다른 데선 볼 수 없는 뉴습니다. 보도자료를 좀 더 분석하거나 해서 나온 뉴스가 아니라, 어딘가에 숨어 있는 데이터를 찾아내 보도하는 거죠.”
이러다 보니 지금까지는 받아 쓸 수밖에 없었던 정부의 발표를, 역으로 검증하는 수준까지 가능해졌습니다.
한 예로, 우리나라에서 가장 공신력 있는 부동산 시세 정보는 국토부가 공개하는 실거래갑니다.
그런데 이게 엉터리였다는 걸 한 언론사가 9년치 가격 정보를 수집하고 비교분석해 밝혀내기도 했습니다.
<녹취> 뉴스타파 (01.09 국토교통부 실거래가 담당자) : “오류를 지금 수정 중에 있고요, 수정할 수 있게 도와주셔서 감사합니다.”
<인터뷰> 김태형 (KBS 데이터저널리즘팀 기자) : "보도자료 자체가 또 데이터가 바탕이 된 보도자료가 되게 많아요. 근데 거기에 들어가 있는 데이터로는 특정 이해관계가 얽혀 있는 경우가 많은 거죠. 그런 건 거꾸로 언론에서 이 데이터 활용이 올바르게 적용이 된 건지 검증을 해주는 작업이 필요합니다"
<질문>
데이터를 기반으로 검증된 사실을 보도하면 그만큼 객관성과 정확성을 높일 수 있지 않습니까. 그렇다면 해외에선 데이터 저널리즘이 어떻게 활용되고 있습니까?
<답변>
우리나라는 저널리즘의 기본인 권력과 정부에 대한 감시와 비판에 좀 더 집중하는 데 비해,
영국이나 미국에선 의료 체계나 빈곤 문제 같은 사회 기반 시스템에 주목하는 경향이 뚜렷합니다. 또 뉴스 소비자들을 직접 참여시키기 위한 노력이 다양하게 시도되고 있습니다.
<리포트>
2008년에 설립된 미국의 비영리 탐사보도 매체, '프로퍼블리카'
퓰리처상을 받은 최초의 인터넷 언론이자, 기자 한 명이 1년간 쓰는 평균 기사 수가 3개에 불과할 정도로 지독한 취재와 정보수집을 바탕으로 탐사보도의 표본으로 급부상하고 있습니다.
<녹취> "오로지 독자의 신뢰만을 추구"
미국 전역의 의료인 160만 명이 작성한 처방전 12억 건을 분석한 보도가 그 대표적인 사롑니다.
의사들이 대형 제약회사로부터 큰 후원금을 받고 그 대가성으로 해당 브랜드의 값비싼 약을 처방해주고 있다고 연속 보도했는데, 여기에 그치지 않고 자료를 데이터베이스로 구축해 개방했습니다.
독자들이 자신의 주치의나, 관심 지역을 검색하면 문제 있는 의사와 처방된 약품명, 가격까지 확인할 수 있습니다.
미주 한인사회도 여기서 한인 의사들을 검색한 뒤 그 결과를 공유했습니다.
<녹취> LA중앙일보 (2014년 4월 11일) : "이 데이터베이스에 본지 조사 대상인 한인 의사 260명을 검색한 결과 85명이 제약회사로부터 후원금을 받았다. 셋 중 한 명꼴이다."
이처럼 데이터 저널리즘이 미국과 영국에서 융성할 수 있는 건, 활용 가능한 형태의 가치 있는 데이터가 많기 때문입니다.
미국과 영국은 이미 5-6년 전 방대한 공공 데이터를 축적하는 단일한 체제를 갖췄습니다. 그리고 정부기관의 데이터를 활용가능한 형태로, 가능한 통일된 양식으로 제공하고 있습니다.
정부뿐만 아니라 언론 스스로도 데이터가 지닌 맹점을 늘 경계할 때 언론으로서 신뢰와 가치를 유지할 수 있다고, 전문가들은 조언합니다.
<인터뷰> 신동희 (성균관대 대학원 인터랙션사이언스학과 교수) : "데이터 저널리즘이 진정한 저널리즘의 하나의 모델로서 정착되기 위해서는 전적인 투명성의 확보가 이루어져야 됩니다. 정부가 정보를 데이터를 공개하고자 하는 어떤 의지와 언론사 간에도 우리가 데이터를 이렇게 해석을 했다. 이렇게 데이터를 모아서 이런 식으로 분석을 했다는, 어떤 그 과정에 대한 절차가 확보가 돼야 되고..."
<질문>
언론이 데이터를 기반으로 좋은 기사를 쓰려면 우선 미국과 영국처럼 공공 데이터를 축적해 공개하는 게 중요하다는 얘긴데, 우리나라의 상황은 어떻습니까?
<답변>
아직은 갈 길이 멀다는 게 언론계 전반적인 분위기입니다. 질문 하나 드려볼게요. 다음 달이죠, 매년 3월이면 고위 공직자 재산공개가 이뤄지는데, 정부가 공개하는 공식 문서는 어떻게 볼 수 있을까요?
<질문>
관보나 정부 사이트에서 볼 수 있지 않나요?
<답변>
맞습니다. 그럼 보통 인터넷 포털 사이트에서, '국회의원 재산공개' 등으로 검색을 하면 그 사이트나 문서가 나와야 되지 않습니까? 그런데 아무리 검색을 해도 정부 사이트나 공식 문서는 찾을 수 없었는데요, 그 이유가 좀 황당합니다.
<리포트>
대표 인터넷 포털 두 곳에서 다양한 검색어로 입력해봤습니다.
개인 블로그와 카페만 검색되고, 공신력 있는 정부의 공식 사이트나 문서는 어디에서도 찾을 수 없습니다.
사이트 검색이 차단돼 있기 때문입니다.
<인터뷰> 신동희 (성균관대 대학원 인터랙션사이언스학과 교수) : “가장 큰 문제는, 공개된 데이터인데 대중들이 그 정보를 쉽게 접근할 수 없다는 것이죠. 정부는 이제 웹사이트를 통해서 공개를 했다고 하지만, 그런 것들이 어떤 글자가 작은 형태로 되어 있다거나 심지어 우리가 검색할 수 없는 형태의 데이터라는 것이죠.”
고위 공직자의 재산 내역은 법에 명시된 공개 정보지만 포털 사이트가 데이터 검색의 80%를 차지하는 우리나라의 특성상 이 정보는 비공개 정보인 셈입니다.
어렵게 찾아내도 문제입니다. 대부분 데이터가 활용하기 어려운 PDF 파일 형식으로 돼 있습니다.
<인터뷰> 권혜진 (뉴스타파 데이터저널리즘연구소 소장) : "PDF에 있는 자료들은 기계가 읽을 수 있는 형태가 아니죠. 따라서 검색하기가 어렵습니다. 그래서 공개는 했는데 검색이 안 되는 경우도 굉장히 많죠. 아쉬운 점은 국민들이 알고 싶어 하는, 뉴스 가치가 큰 그런 정보들은 여전히 접근하기가 어렵고 불편하게 돼 있단 사실입니다."
이뿐만이 아닙니다. 재산 관련 페이지만 삭제해 버렸거나, 몽땅 백지로 올려놓은 경우도 있습니다.
우리 정부는 지난 2013년 공공 정보를 적극 개방, 공유하겠다며 ‘정부 3.0’ 추진 계획을 발표했습니다.
국가 기관의 모든 정보는 공개를 원칙으로 하고 공개 문서는 생산과 동시에 원문까지 공개하는 등 구체적인 내용이 담겼습니다.
하지만 1년 반이 지난 지금도 여전히 미흡하다는 평갑니다.
그러다 보니 언론도 고전 중입니다.
데이터 저널리즘을 주창하며 과감히 전담 부서를 편성한 언론사 가운데 지금도 기사를 꾸준히 내놓으며 조직을 유지하는 곳은 거의 없습니다.
<인터뷰> 박대민 (한국언론재단 선임연구원) : "이렇게 데이터를 활용하기가 힘들고 여러 가지 풀어야 할 사항들도 많고 이런 상황에서, 자체 자원이나 인력을 새롭게 투자해서 분석에 들어가기 쉽지 않은 상황이 된 겁니다. 인적, 금전적으로 여기에 투입할 만한 여력이 있는 언론사가 많지 않은 거죠"
데이터 자체가 갖고 있는 가치와 의미는 갈수록 중요해지고 있습니다.
하지만 역시 중요한 것은, 기자가 현장을 발로 뛰고 정확한 시각과 판단을 갖추고 데이터의 이면을 들여다 볼 때, 비로소 진정한 데이터 저널리즘도 실현될 수 있습니다.
-
-

류란 기자 nany@kbs.co.kr
류란 기자의 기사 모음
-
이 기사가 좋으셨다면
-
좋아요
0
-
응원해요
0
-
후속 원해요
0
오늘의 핫 클릭
실시간 뜨거운 관심을 받고 있는 뉴스
헤드라인





이 기사에 대한 의견을 남겨주세요.