










글로벌 빅테크의 인공지능 경쟁이 치열합니다. 챗GPT가 열어젖힌 대화형 인공지능 시장에 구글 '바드', 마이크로소프트 '빙'에 이어 메타(구 페이스북)까지 참전했습니다.
최근 메타가 발표한 인공지능 '라마(LLaMA)는 챗GPT와 같은 대화형 인공지능입니다. 많은 양의 언어 데이터를 사전학습해 마치 인간처럼 대화합니다.
메타 측은 라마가 챗GPT보다 매개변수가 적은데도 성능은 더 뛰어나다고 강조했습니다. 매개변수는 인공지능의 분석 기본 단위로, 매개변수가 많을수록 인공지능은 분석이 정교해지고 언어구사능력이 높아진다고 평가됩니다. 챗GPT의 매개변수는 1,750억 개입니다.
라마는 챗GPT처럼 단일 모델이 아닌, 매개변수별로 여러 모델로 출시됐습니다. 라마의 매개변수는 70억 개, 130억 개, 330억 개, 650억 개로 나뉩니다. 가장 많은 650억 개 모델이라도 챗GPT의 절반보다 적습니다.
메타는 적은 매개변수 규모의 한계를 사전학습 데이터양으로 극복했다고 설명합니다. 인공지능 라마가 사전학습한 데이터는 70억, 130억 개 모델이 1조 개 토큰(인공지능 데이터 단위)이고, 330억, 650억 개 모델은 1조 4,000억 개 토큰입니다. 토큰은 인공지능 학습 데이터 단위로, '단어'보다 작은 단위입니다.
챗GPT를 훈련한 데이터는 7,000억 개 토큰으로 알려져 있습니다. 라마의 사전학습 데이터양이 많게는 챗GPT의 2배 정도인 셈입니다.
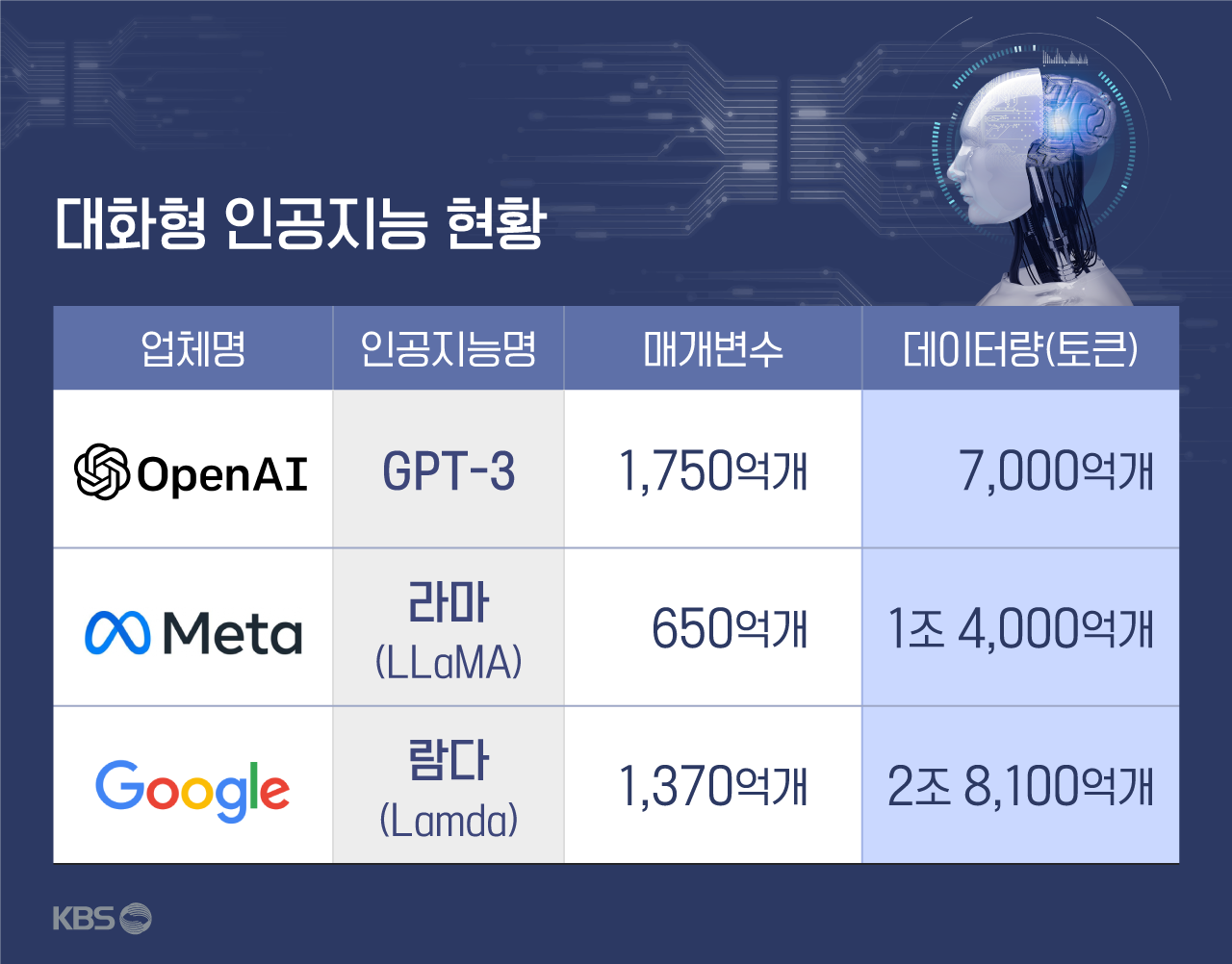
메타는 라마 130억 개 모델이 오픈AI(챗GPT 개발사)의 GPT-3보다 성능이 뛰어나다고 설명했습니다. GPT-3는 2020년 오픈AI가 발표한 인공지능으로 챗GPT의 기술적 기반이 된 모델입니다. 매개변수 수는 GPT-3와 챗GPT 모두 1,750억 개로 같습니다.
다만, 라마는 현재 관련 논문만 공개된 상태로 아직 직접 이용해 볼 수는 없습니다. 메타 측은 "라마는 과학자·엔지니어를 위해 비영리 라이선스로 제공할 예정"이라고 밝혔습니다.
■ 방대한 학습데이터..보이지 않는 '한국어'
눈에 띄는 점은, 라마의 사전학습 데이터 묶음입니다. 라마는 웹상에 공개된 데이터만을 사용했는데, 커먼크롤 재단 데이터 67.0%, 깃허브 4.5%, 위키백과 4.5% 등입니다.
이들 데이터는 20개 언어로 구성됐습니다. 구체적으로는 영어, 프랑스어, 스페인어, 독일어, 러시아어, 이탈리아어, 네덜란드어, 폴란드어, 포르투갈어, 루마니아어, 슬로베니아어, 세르비아어, 스웨덴어, 우크라이나어, 불가리아어, 카탈로니아어, 체코어, 덴마크어, 크로아티아어, 헝가리어 등입니다.
한국어는 없습니다.
이와 관련, 메타는 "라틴어와 키릴어 알파벳을 사용하는 언어 중심으로 가장 많이 쓰이는 20개 언어를 선택했다"고만 설명했습니다.
최근 주요 빅테크의 인공지능 전쟁에서 '한국어'가 보이지 않는 점은 최근 폭발적 인기를 끈 챗GPT도 마찬가지입니다.
챗GPT 개발사인 오픈AI는 이전 모델인 'GPT-3'를 기반 삼아 챗GPT를 개발했는데, GPT-3의 사전학습 데이터 언어별 비율이 공개돼 있습니다.
이 자료를 보면, 오픈AI는 사전학습 데이터로 위키백과, 신문기사 등을 이용했는데 단어별로 봤을 때 영어의 비율이 92.6%로 가장 많습니다. 이어 프랑스어(1.82%), 독일어(1.47%) 순입니다.
한국어는 28위인데 비율이 0.01697%입니다. 0.02%에도 미치지 못합니다.
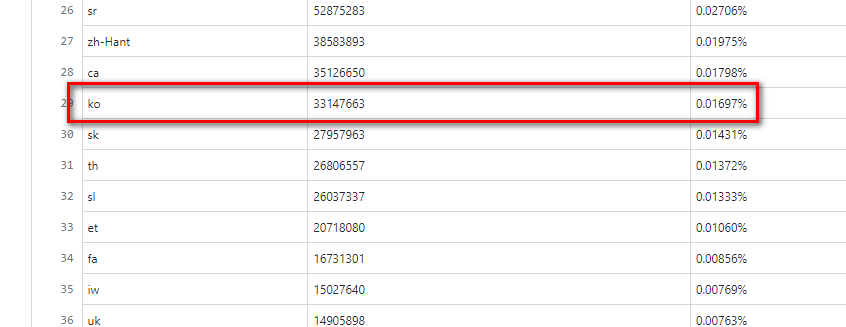 ‘GPT-3’ 사전학습 데이터의 한국어 비율
‘GPT-3’ 사전학습 데이터의 한국어 비율참고로, 전 세계 언어를 조사하는 국제언어센터에 따르면 전 세계 언어는 7,117개로 이 가운데 한국어 사용자 수는 약 8,010만 명으로 알려졌습니다. 전 세계 인구 가운데 1.13%에 해당합니다.
또 CNN에 따르면, 글로벌 언어학습 어플리케이션 '듀오링고' 조사 결과 한국어는 지난해 이 앱에서 7번째로 많이 학습된 언어였습니다. 이는 K팝과 드라마 등 한국 콘텐츠 열풍에 따른 '한류' 때문이라는 게 CNN의 분석입니다.
■ 미래 인공지능 시장, 한국어 비중 더 커져야
대화형 인공지능에게 사전학습 데이터는 핵심 원동력입니다. 인공지능은 막대한 양의 언어 데이터를 자연어처리기술(NLP)을 이용해 딥러닝 학습합니다. 이 학습 과정을 통해 이용자의 질문을 알아듣고, 마치 인간처럼 답변하는 법을 익힌다고 볼 수 있습니다.
그런데 이 사전학습 데이터에 한국어 자료가 적거나 없다면 인공지능은 그만큼 한국어를 모르고, 한국어로 설명된 자료들에 무지하게 됩니다.
그에 따른 영향으론, 우선 한국어 관련 질문을 처리하는 데 시간이 더 소요될 수 있습니다. 이는 인공지능이 학습한 데이터가 충분하지 않기 때문에 그만큼 성능이 다른 언어 대비 낮기 때문입니다. 현재 챗GPT에게 한국어로 질문하면 영어 질문과 비교해 답변 속도가 느린 것도 그래서입니다.
번역, 긴 문장 요약, 작문 등 한국어를 이용한 언어처리 기능도 다른 언어 대비 떨어질 수 있습니다. 앞으로 인공지능 기술이 발전할수록 다양한 분야에서 활용될 가능성이 크다는 점에서, 이는 치명적이라고 볼 수 있습니다.
이와 관련, 국내 업체의 노력도 있습니다. 네이버는 챗GPT보다 한국어를 6,500배 더 많이 학습한 인공지능을 오는 7월 공개하겠다는 입장입니다.
다만, 구글이나 마이크로소프트 같은 주요 빅테크의 인공지능 모델이 글로벌 표준으로 자리 잡을 가능성이 크다는 점에서, 해당 인공지능에서 한국어 비중이 더 커져야 한다는 지적은 여전합니다.
■ 제보하기
▷ 카카오톡 : 'KBS제보' 검색, 채널 추가
▷ 전화 : 02-781-1234, 4444
▷ 이메일 : kbs1234@kbs.co.kr
▷ 유튜브, 네이버, 카카오에서도 KBS뉴스를 구독해주세요!
- [테크톡] ‘한국어’는 뒷전?…격렬해진 AI 전쟁
-
- 입력 2023-03-01 08:00:18
글로벌 빅테크의 인공지능 경쟁이 치열합니다. 챗GPT가 열어젖힌 대화형 인공지능 시장에 구글 '바드', 마이크로소프트 '빙'에 이어 메타(구 페이스북)까지 참전했습니다.
최근 메타가 발표한 인공지능 '라마(LLaMA)는 챗GPT와 같은 대화형 인공지능입니다. 많은 양의 언어 데이터를 사전학습해 마치 인간처럼 대화합니다.
메타 측은 라마가 챗GPT보다 매개변수가 적은데도 성능은 더 뛰어나다고 강조했습니다. 매개변수는 인공지능의 분석 기본 단위로, 매개변수가 많을수록 인공지능은 분석이 정교해지고 언어구사능력이 높아진다고 평가됩니다. 챗GPT의 매개변수는 1,750억 개입니다.
라마는 챗GPT처럼 단일 모델이 아닌, 매개변수별로 여러 모델로 출시됐습니다. 라마의 매개변수는 70억 개, 130억 개, 330억 개, 650억 개로 나뉩니다. 가장 많은 650억 개 모델이라도 챗GPT의 절반보다 적습니다.
메타는 적은 매개변수 규모의 한계를 사전학습 데이터양으로 극복했다고 설명합니다. 인공지능 라마가 사전학습한 데이터는 70억, 130억 개 모델이 1조 개 토큰(인공지능 데이터 단위)이고, 330억, 650억 개 모델은 1조 4,000억 개 토큰입니다. 토큰은 인공지능 학습 데이터 단위로, '단어'보다 작은 단위입니다.
챗GPT를 훈련한 데이터는 7,000억 개 토큰으로 알려져 있습니다. 라마의 사전학습 데이터양이 많게는 챗GPT의 2배 정도인 셈입니다.
메타는 라마 130억 개 모델이 오픈AI(챗GPT 개발사)의 GPT-3보다 성능이 뛰어나다고 설명했습니다. GPT-3는 2020년 오픈AI가 발표한 인공지능으로 챗GPT의 기술적 기반이 된 모델입니다. 매개변수 수는 GPT-3와 챗GPT 모두 1,750억 개로 같습니다.
다만, 라마는 현재 관련 논문만 공개된 상태로 아직 직접 이용해 볼 수는 없습니다. 메타 측은 "라마는 과학자·엔지니어를 위해 비영리 라이선스로 제공할 예정"이라고 밝혔습니다.
■ 방대한 학습데이터..보이지 않는 '한국어'
눈에 띄는 점은, 라마의 사전학습 데이터 묶음입니다. 라마는 웹상에 공개된 데이터만을 사용했는데, 커먼크롤 재단 데이터 67.0%, 깃허브 4.5%, 위키백과 4.5% 등입니다.
이들 데이터는 20개 언어로 구성됐습니다. 구체적으로는 영어, 프랑스어, 스페인어, 독일어, 러시아어, 이탈리아어, 네덜란드어, 폴란드어, 포르투갈어, 루마니아어, 슬로베니아어, 세르비아어, 스웨덴어, 우크라이나어, 불가리아어, 카탈로니아어, 체코어, 덴마크어, 크로아티아어, 헝가리어 등입니다.
한국어는 없습니다.
이와 관련, 메타는 "라틴어와 키릴어 알파벳을 사용하는 언어 중심으로 가장 많이 쓰이는 20개 언어를 선택했다"고만 설명했습니다.
최근 주요 빅테크의 인공지능 전쟁에서 '한국어'가 보이지 않는 점은 최근 폭발적 인기를 끈 챗GPT도 마찬가지입니다.
챗GPT 개발사인 오픈AI는 이전 모델인 'GPT-3'를 기반 삼아 챗GPT를 개발했는데, GPT-3의 사전학습 데이터 언어별 비율이 공개돼 있습니다.
이 자료를 보면, 오픈AI는 사전학습 데이터로 위키백과, 신문기사 등을 이용했는데 단어별로 봤을 때 영어의 비율이 92.6%로 가장 많습니다. 이어 프랑스어(1.82%), 독일어(1.47%) 순입니다.
한국어는 28위인데 비율이 0.01697%입니다. 0.02%에도 미치지 못합니다.
참고로, 전 세계 언어를 조사하는 국제언어센터에 따르면 전 세계 언어는 7,117개로 이 가운데 한국어 사용자 수는 약 8,010만 명으로 알려졌습니다. 전 세계 인구 가운데 1.13%에 해당합니다.
또 CNN에 따르면, 글로벌 언어학습 어플리케이션 '듀오링고' 조사 결과 한국어는 지난해 이 앱에서 7번째로 많이 학습된 언어였습니다. 이는 K팝과 드라마 등 한국 콘텐츠 열풍에 따른 '한류' 때문이라는 게 CNN의 분석입니다.
■ 미래 인공지능 시장, 한국어 비중 더 커져야
대화형 인공지능에게 사전학습 데이터는 핵심 원동력입니다. 인공지능은 막대한 양의 언어 데이터를 자연어처리기술(NLP)을 이용해 딥러닝 학습합니다. 이 학습 과정을 통해 이용자의 질문을 알아듣고, 마치 인간처럼 답변하는 법을 익힌다고 볼 수 있습니다.
그런데 이 사전학습 데이터에 한국어 자료가 적거나 없다면 인공지능은 그만큼 한국어를 모르고, 한국어로 설명된 자료들에 무지하게 됩니다.
그에 따른 영향으론, 우선 한국어 관련 질문을 처리하는 데 시간이 더 소요될 수 있습니다. 이는 인공지능이 학습한 데이터가 충분하지 않기 때문에 그만큼 성능이 다른 언어 대비 낮기 때문입니다. 현재 챗GPT에게 한국어로 질문하면 영어 질문과 비교해 답변 속도가 느린 것도 그래서입니다.
번역, 긴 문장 요약, 작문 등 한국어를 이용한 언어처리 기능도 다른 언어 대비 떨어질 수 있습니다. 앞으로 인공지능 기술이 발전할수록 다양한 분야에서 활용될 가능성이 크다는 점에서, 이는 치명적이라고 볼 수 있습니다.
이와 관련, 국내 업체의 노력도 있습니다. 네이버는 챗GPT보다 한국어를 6,500배 더 많이 학습한 인공지능을 오는 7월 공개하겠다는 입장입니다.
다만, 구글이나 마이크로소프트 같은 주요 빅테크의 인공지능 모델이 글로벌 표준으로 자리 잡을 가능성이 크다는 점에서, 해당 인공지능에서 한국어 비중이 더 커져야 한다는 지적은 여전합니다.
-
-

이승종 기자 argo@kbs.co.kr
이승종 기자의 기사 모음
-
이 기사가 좋으셨다면
-
좋아요
0
-
응원해요
0
-
후속 원해요
0
오늘의 핫 클릭
실시간 뜨거운 관심을 받고 있는 뉴스
헤드라인





많이 본 뉴스
-
각 플랫폼에서 최근 1시간 동안 많이 본 KBS 기사를 제공합니다.
-
각 플랫폼에서 최근 1시간 동안 많이 본 KBS 기사를 제공합니다.
-
각 플랫폼에서 최근 1시간 동안 많이 본 KBS 기사를 제공합니다.
이 기사에 대한 의견을 남겨주세요.